5 самых мощных суперкомпьютеров: для чего они нужны?

Модели с огромной производительностью, укомплектованные тысячами процессоров и десятками гигабайт ОЗУ, называются суперкомпьютерами. Самые мощные можно найти в списке TOP500, где первые 5 мест занимают американские модели Summit и Sierra, китайские ЭВМ Sunway TaihuLight и Тяньхэ-2, а также швейцарский Piz Daint.
Что такое суперкомпьютер
СуперЭВМ – название, которое получают специализированные вычислительные машины, превосходящие по характеристикам и скорости вычисления большинство обычных компьютеров.
Суперкомпьютер состоит из большого количества многоядерных систем, объединенных в общую систему для получения высокой производительности. Еще одно отличие от обычных ПК – большие размеры. Техника располагается в нескольких помещениях, занимая целые этажи и здания.
Первым настоящим суперкомпьютером считается собранный в 1974 году в США ПК Cray-1. Благодаря поддержке векторных операций модель выполняла до 180 млн вычислений с плавающей точкой в секунду (флопс). Большая часть суперЭВМ по-прежнему собирается и используется в Соединенных Штатах, следующими по количеству такой техники идут Китай и Япония.
Назначение суперкомпьютеров
Суперкомпьютеры решают разнообразные задачи – от сложных математических расчетов и обработки огромных массивов данных до моделирования искусственного интеллекта. Есть модели, воспроизводящие «архитектуру» человеческого мозга. На СуперЭВМ проектируют промышленное оборудование и электронику, синтезируют новые материалы и делают научные открытия.
Автомобилестроительные компании используют суперкомпьютеры для имитации результатов краш-тестов, экономя средства на настоящих испытаниях. Подходит такая мощная техника и для разработки новых двигателей, позволяя моделировать специальный температурный режим и процессы деформации. С ее же помощью можно прогнозировать метеорологические явления и даже землетрясения.
1. Summit
Суперкомпьютер Summit, созданный американской компанией IBM для Национальной лаборатории в Окридже. Технику ввели в эксплуатацию летом 2018 года, заменив модель Titan, которая считалась самой производительной американской СуперЭВМ. Разработка лучшего современного суперкомпьютера обошлась американскому правительству в 200 млн долларов.
Устройство потребляет около 15 МВт электроэнергии – столько, сколько вырабатывает небольшая ГЭС. Для охлаждения вычислительной системы используется 15,1 кубометра циркулирующей по трубкам воды. Сервера IBM расположены на площади около 930 кв.м – территория, которую занимают 2 баскетбольные площадки. Для работы суперкомпьютера используется 220 км электрокабелей.

Производительность компьютера обеспечивается 9216 процессорами модели IBM POWER9 и 27648 графическими чипами Tesla V100 от Nvidia. Система получила целых 512 Гбайт оперативной и 250 Пбайт постоянной памяти (интерфейс 2,5 Тбайт/с). Максимальная скорость вычислений – 200 Пфлопс, а номинальная производительность – 143,5 Пфлопс.
По словам американских ученых, запуск в работу модели Summit позволил повысить вычислительные мощности в сфере энергетики, экономическую конкурентоспособность и национальную безопасность страны. Среди задач, которые будут решаться с помощью суперкомпьютера, отмечают поиск связи между раковыми заболеваниями и генами живого организма, исследование причин появления зависимости от наркотиков и климатическое моделирование для составления точных прогнозов погоды.
2. Sierra
Второй американский суперкомпьютер Sierra (ATS-2) тоже выпущен в 2018 году и обошелся Соединенным Штатам примерно в 125 миллионов долларов. По производительности он считается вторым, хотя по среднему и максимальному уровню скорости вычислений сравним с китайской моделью Sunway TaihuLight.
Расположена СуперЭВМ на территории Национальной лаборатории имени Э. Лоуренса в Ливерморе. Общая площадь, которую занимает оборудование, составляет около 600 кв.м. Энергопотребление вычислительной системы – 12 МВт. И уже по соотношению производительность к расходу электричества компьютер заметно обогнал конкурента из КНР.

В системе используется 2 вида процессоров – серверные ЦПУ IBM Power 9 и графические Nvidia Volta. Благодаря этим чипам удалось повысить и энергоэффективность, и производительность. 4320 узлов со 190 тысячами ядер обеспечивают вычисления на скорости 94,64 петафлопс. Максимальная производительность – 125,712 Пфлопс или 125 квадриллионов операций с плавающей точкой в секунду.
Новую систему предполагается использовать в научных целях. В первую очередь – для расчетов в области создания ядерного оружия, заменяя вычислениями подземные испытания. Инженерные расчеты с помощью Sierra позволят разобраться и с ключевыми вопросами в области физики, знание которых позволит совершить ряд научных открытий.
3. Sunway TaihuLight
Китайская СуперЭВМ удерживала лидирующую позицию в рейтинге TOP500 с 2016 до 2018 года. В соответствии с тестами LINPACK ее считали самым производительным суперкомпьютером, минимум в полтора раза превосходящим ближайшего конкурента и втрое опережающим самую производительную американскую модель Titan. Разработка и строительство вычислительной системы обошлось в 1,8 млрд. юаней или 270 млн долларов. Инвесторами проекта были правительство Китая, администрация китайской провинции Цзянсу и города Уси.

Суперкомпьютер потребляет 15,3 МВт электроэнергии и занимает площадь 605 кв.м. Расположен он на территории города Уси, в национальном суперкомпьютерном центре. Название модели дали в честь расположенного рядом озера Тайху, третьего по величине пресноводного водоема Китая.
Наличие в конструкции ЭВМ 41 тысячи процессоров SW26010 и 10,6 миллиона ядер позволяет ей проводить расчеты со скоростью 93 Пфлопс. Максимальная производительность – 125 Пфлопс. Переход на чипы китайского производства потребовал от разработчиков создания полностью новой системы. До этого предполагалось в 2 раза повысить производительность другой китайской СуперЭВМ Тяньхэ-2, но эти намерения пришлось изменить из-за проблем с поставками процессоров Intel из США.
Модель Sunway TaihuLight применяется для выполнения сложных вычислений в области медицины, горнодобывающей промышленности и производстве. С помощью вычислительной машины прогнозируют погоду, исследуют новые лекарства и анализируют «большие данные» – массивы информации, обработать которые не получится даже у самого мощного серийного компьютера.
4. Тяньхэ-2
Суперкомпьютер Tianhe-2 («Млечный путь»), а, точнее, уже дополненная и модернизированная версия 2А, была разработана сотрудниками компании Inspur и научно-технического университета Народно-освободительной армии Китая. В июле 2013 года модель считалась самой производительной в мире и уступила пальму первенства только другому китайскому компьютеру TaihuLight. На сборку ЭВМ потратили около 200 млн долларов.
Сначала вычислительная система находилась на территории университета, а затем была перемещена в суперкомпьютерный центр в Гуанчжоу. Общая площадь, которую она занимает – около 720 кв. м. Энергопотребление модели составляет 17,8 МВт, что делает ее использование менее выгодным по сравнению с более современными версиями.

Техника построена на базе 80 тысяч ЦПУ Intel Xeon и Xeon Phi. Объем оперативной памяти – 1400 Гбайт, количество вычислительных ядер – больше 3 миллионов. На суперкомпьютере установлена операционная система Kylin Linux. Первые показатели работы системы – 33,8 Пфлопс, современная модификация достигает скорости вычислений 61,4 Пфлопс, максимальная – 100,679 Пфлопс.
СуперЭВМ создали по требованию китайского правительства, его основными задачами являются расчеты для проектов национального масштаба. С помощью системы решаются вопросы безопасности Китая, выполняется моделирование и анализ большого количества научной информации.
5. Piz Daint
Суперкомпьютер Piz Daint достаточно долго (с 2013 до 2018 года) занимал третье место в рейтинге самых мощных вычислительных систем в мире. В то же время он остается самым производительным компьютером Европы. Стоимость проекта составила около 40 млн швейцарских франков.
Модель получила название в честь одноименной территории в Швейцарских Альпах и находится в национальном суперкомпьютерном центре. Оборудование, из которого состоит СуперЭВМ, располагается в 28 стойках. Для работы техники требуется 2,3 МВт электричества, и по этому показателю Piz Daint обеспечивает лучшую удельную производительность – 9,2 Пфлопс/МВт.

В составе ЭВМ есть другой суперкомпьютер Piz Dora, сначала работавший отдельно. После объединения мощностей швейцарские разработчики получили вычислительную систему с 362 тысячами ядер (процессоры Xeon E5-2690v3) номинальной производительностью 21,23 Пфлопс. Максимальная скорость работы – 27 Пфлопс.
Основные задачи суперкомпьютера – расчеты для исследований в области геофизики, метеорологии, физике и климатологии. Одно из приложений для ЭВМ, COSMO, представляет собой метеорологическую модель и используется метеослужбами Германии и Швейцарии для получения высокоточных прогнозов погоды.
Высокопроизводительные вычисления: проблемы и решения
Компьютеры, даже персональные, становятся все сложнее. Не так уж давно в гудящем на столе ящике все было просто — чем больше частота, тем больше производительность. Теперь же системы стали многоядерными, многопроцессорными, в них появились специализированные ускорители, компьютеры все чаще объединяются в кластеры.
Зачем? Как во всем этом многообразии разобраться?
Что значит SIMD, SMP, GPGPU и другие страшные слова, которые встречаются все чаще?
Каковы границы применимости существующих технологий повышения производительности?
Введение
Откуда такие сложности?
Формула производительности
Возьмем самую общую формулу производительности:
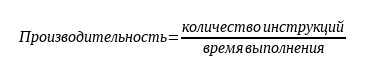
Видим, что производительность можно измерять в количестве выполняемых инструкций за секунду.
Распишем процесс поподробнее, введем туда тактовую частоту:

Первая часть полученного произведения — количество инструкций, выполняемых за один такт (IPC, Instruction Per Clock), вторая — количество тактов процессора в единицу времени, тактовая частота.
Таким образом, для увеличения производительности нужно или поднимать тактовую частоту или увеличивать количество инструкций, выполняемых за один такт.
Т.к. рост частоты остановился, придется увеличивать количество исполняемых «за раз» инструкций.
Включаем параллельность
Как же увеличить количество инструкций, исполняемых за один такт?
Очевидно, выполняя несколько инструкций за один раз, параллельно. Но как это сделать?
Все сильно зависит от выполняемой программы.
Если программа написана программистом как однопоточная, где все инструкции выполняются последовательно, друг за другом, то процессору (или компилятору) придется «думать за человека» и искать части программы, которые можно выполнить одновременно, распараллелить.
Параллелизм на уровне инструкций
Возьмем простенькую программу:
a = 1
b = 2
c = a + b
Первые две инструкции вполне можно выполнять параллельно, только третья от них зависит. А значит — всю программу можно выполнить за два шага, а не за три.
Процессор, который умеет сам определять независимые и непротиворечащие друг другу инструкции и параллельно их выполнять, называется суперскалярным.
Очень многие современные процессоры, включая и последние x86 — суперскалярные процессоры, но есть и другой путь: упростить процессор и возложить поиск параллельности на компилятор. Процессор при этом выполняет команды «пачками», которые заготовил для него компилятор программы, в каждой такой «пачке» — набор инструкций, которые не зависят друг от друга и могут исполняться параллельно. Такая архитектура называется VLIW (very long instruction word — «очень длинная машинная команда»), её дальнейшее развитие получило имя EPIC (explicitly parallel instruction computing) — микропроцессорная архитектура с явным параллелизмом команд)
Самые известные процессоры с такой архитектурой — Intel Itanium.
Есть и третий вариант увеличения количества инструкций, выполняемых за один такт, это технология Hyper Threading В этой технологии суперскалярный процессор самостоятельно распараллеливает не команды одного потока, а команды нескольких (в современных процессорах — двух) параллельно запущенных потоков.
Т.е. физически процессорное ядро одно, но простаивающие при выполнении одной задачи мощности процессора могут быть использованы для выполнения другой. Операционная система видит один процессор (или одно ядро процессора) с технологией Hyper Threading как два независимых процессора. Но на самом деле, конечно, Hyper Threading работает хуже, чем реальные два независимых процессора т.к. задачи на нем будут конкурировать за вычислительные мощности между собой.
Технологии параллелизма на уровне инструкций активно развивались в 90е и первую половину 2000х годов, но в настоящее время их потенциал практически исчерпан. Можно переставлять местами команды, переименовывать регистры и использовать другие оптимизации, выделяя из последовательного кода параллельно исполняющиеся участки, но все равно зависимости и ветвления не дадут полностью автоматически распараллелить код. Параллелизм на уровне инструкций хорош тем, что не требует вмешательства человека — но этим он и плох: пока человек умнее микропроцессора, писать по-настоящему параллельный код придется ему.
Параллелизм на уровне данных
Векторные процессоры
Мы уже упоминали скалярность, но кроме скаляра есть и вектор, и кроме суперскалярных процессоров есть векторные.
Векторные процессоры выполняют какую-то операцию над целыми массивами данных, векторами. В «чистом» виде векторные процессоры применялись в суперкомьютерах для научных вычислений в 80-е годы.
По классификации Флинна, векторные процессоры относятся к SIMD — (single instruction, multiple data — одиночный поток команд, множественный поток данных).
В настоящее время в процессорах x86 реализовано множество векторных расширений — это MMX, 3DNow!, SSE, SSE2 и др.
Вот как, например, выглядит умножение четырех пар чисел одной командой с применением SSE:
float a[4] = < 300.0, 4.0, 4.0, 12.0 >;
float b[4] = < 1.5, 2.5, 3.5, 4.5 >;
__asm <
movups xmm0, a ; // поместить 4 переменные с плавающей точкой из a в регистр xmm0
movups xmm1, b ; // поместить 4 переменные с плавающей точкой из b в регистр xmm1
mulps xmm1, xmm0 ; // перемножить пакеты плавающих точек: xmm1=xmm1*xmm0
movups a, xmm1 ; // выгрузить результаты из регистра xmm1 по адресам a
>;
Таким образом, вместо четырех последовательных скалярных умножений мы сделали только одно — векторное.
Векторные процессоры могут значительно ускорить вычисления над большими объемами данных, но сфера их применимости ограничена, далеко не везде применимы типовые операции над фиксированными массивами.
Впрочем, гонка векторизации вычислений далеко не закончена — так в последних процессорах Intel появилось новое векторное расширение AVX (Advanced Vector Extension)
Но гораздо интереснее сейчас выглядят
Графические процессоры
Теоретическая вычислительная мощность процессоров в современных видеокартах растет гораздо быстрее, чем в обычных процессорах (посмотрим знаменитую картинку от NVIDIA) 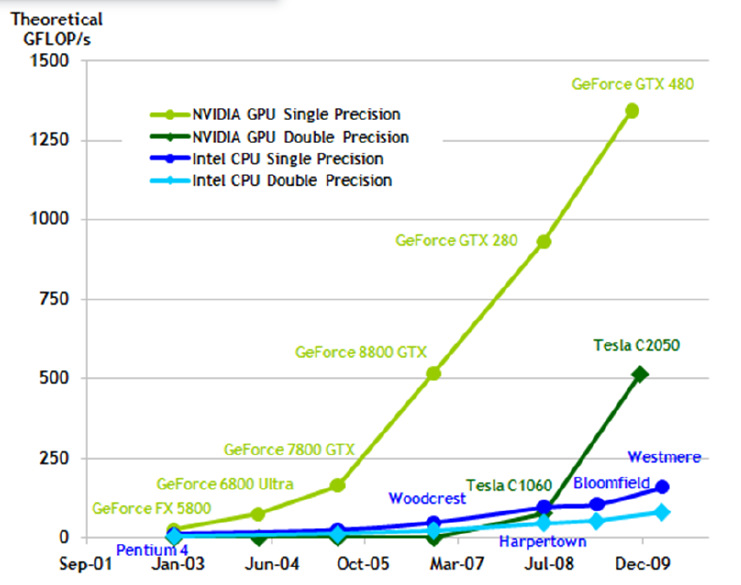
Не так давно эта мощность была приспособлена для универсальных высокопроизводительных вычислений с помощью CUDA/OpenCL.
Архитектура графических процессоров (GPGPU, General Purpose computation on GPU – универсальные расчеты средствами видеокарты), близка к уже рассмотренной SIMD.
Она называется SIMT — (single instruction, multiple threads, одна инструкция — множество потоков). Так же как в SIMD операции производятся с массивами данных, но степеней свободы гораздо больше — для каждой ячейки обрабатываемых данных работает отдельная нить команд.
В результате
1) Параллельно могут выполняться сотни операций над сотнями ячеек данных.
2) В каждом потоке выполняется произвольная последовательность команд, она может обращаться к разным ячейкам.
3) Возможны ветвления. При этом, правда, параллельно могут выполняться только нити с одной и той же последовательностью операций.
GPGPU позволяют достичь на некоторых задачах впечатляющих результатов. но существуют и принципиальные ограничения, не позволяющие этой технологии стать универсальной палочкой-выручалочкой, а именно
1) Ускорить на GPU можно только хорошо параллелящийся по данным код.
2) GPU использует собственную память. Трансфер данных между памятью GPU и памятью компьютера довольно затратен.
3) Алгоритмы с большим количеством ветвлений работают на GPU неэффективно
Мультиархитектуры-
Итак, мы дошли до полностью параллельных архитектур — независимо параллельных и по командам, и по данным.
В классификации Флинна это MIMD (Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных).
Для использования всей мощности таких систем нужны многопоточные программы, их выполнение можно «разбросать» на несколько микропроцессоров и этим достичь увеличения производительности без роста частоты. Различные технологии многопоточности давно применялись в суперкомпьютерах, сейчас они «спустились с небес» к простым пользователям и многоядерный процессор уже скорее правило, чем исключение. Но многоядерность далеко не панацея.
Суров закон, но это закон
Параллельность, это хороший способ обойти ограничение роста тактовой частоты, но у него есть собственные ограничения.
Прежде всего, это закон Амдала, который гласит
Ускорение выполнения программы за счет распараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
Ускорение кода зависит от числа процессоров и параллельности кода согласно формуле

Действительно, с помощью параллельного выполнения мы можем ускорить время выполнения только параллельного кода.
В любой же программе кроме параллельного кода есть и последовательные участки и ускорить их с помощью увеличения количества процессоров не получится, над ними будет работать только один процессор.
Например, если выполнение последовательного кода занимает всего 25% от времени выполнения всей программы, то ускорить эту программу более чем в 4 раза не получится никак.
Давайте построим график зависимости ускорения нашей программы от количества параллельно работающих вычислителей-процессоров. Подставив в формулу 1/4 последовательного кода и 3/4 параллельного, получим 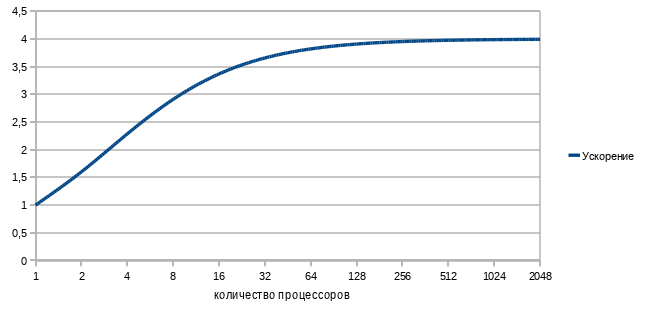
Грустно? Еще как.
Самый быстрый в мире суперкомпьютер с тысячами процессоров и терабайтами памяти на нашей, вроде бы даже неплохо (75%!) параллелящейся задаче, меньше чем вдвое быстрее обычного настольного четырехядерника.
Причем всё еще хуже, чем в этом идеальном случае. В реальном мире затраты обеспечение параллельности никогда не равны нулю и потому при добавлении все новых и новых процессоров производительность, начиная с некоторого момента, начнет падать.
Но как же тогда используется мощь современных очень-очень многоядерных суперкомпьютеров?
Во многих алгоритмах время исполнения параллельного кода сильно зависит от количества обрабатываемых данных, а время исполнения последовательного кода — нет. Чем больше данных требуется обработать, тем больше выигрыш от параллельности их обработки. Потому «загоняя» на суперкомп большие объемы данных получаем хорошее ускорение.
Например перемножая матрицы 3*3 на суперкомпьютере мы вряд ли заметим разницу с обычным однопроцессорным вариантом, а вот умножение матриц, размером 1000*1000 уже будет вполне оправдано на многоядерной машине.
Есть такой простой пример: 9 женщин за 1 месяц не могут родить одного ребенка. Параллельность здесь не работает. Но вот та же 81 женщина за 9 месяцев могут родить (берем максимальную эффективность!) 81 ребенка, т.е.получим максимальную теоретическую производительность от увеличения параллельности, 9 ребенков в месяц или, в среднем, тот же один ребенок в месяц на 9 женщин.
Большим компьютерам — большие задачи!
Мультипроцессор
Мультипроцессор — это компьютерная система, которая содержит несколько процессоров и одно видимое для всех процессоров. адресное пространство.
Мультипроцессоры отличаются по организации работы с памятью.
Системы с общей памятью
В таких системах множество процессоров (и процессорных кэшей) имеет доступ к одной и той же физической оперативной памяти. Такая модель часто называется симметричной мультипроцессорностью (SMP). Доступ к памяти при таком построении системы называется UMA (uniform memory access, равномерный доступ) т.к. любой процессор может обратиться к любой ячейке памяти и скорость этого обращения не зависит от адреса памяти. Однако каждый микропроцессор может использовать свой собственный кэш. 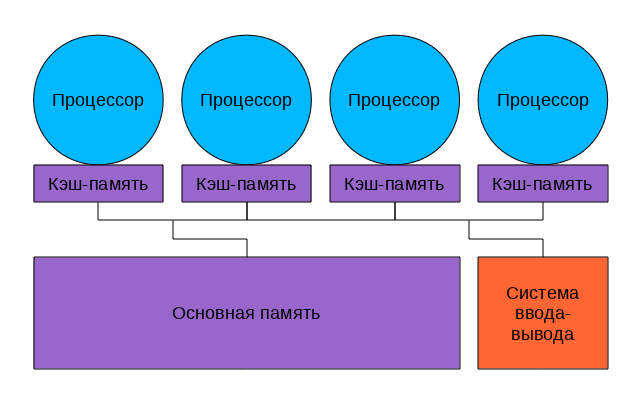
Несколько подсистем кэш-памяти процессоров, как правило, подключены к общей памяти через шину
Посмотрим на рисунок.
Что у нас хорошего?
Любой процессор обращается ко всей памяти и вся она работает одинаково. Программировать для таких систем проще, чем для любых других мультиархитектур. Плохо то, что все процессоры обращаются к памяти через шину, и с ростом числа вычислительных ядер пропускная способность этой шины быстро становится узким местом.
Добавляет головной боли и проблема обеспечения когерентности кэшей.
Когерентность кэша
Допустим, у нас есть многопроцессорный компьютер. Каждый процессор имеет свой кэш, ну, как на рисунке вверху. Пусть некоторую ячейку памяти читали несколько процессоров — и она попала к ним в кэши. Ничего страшного, пока это ячейка неизменна — из быстрых кэшей она читается и как-то используется в вычислениях.
Если же в результате работы программы один из процессоров изменит эту ячейку памяти, чтоб не было рассогласования, чтоб все остальные процессоры «видели» это обновление придется изменять содержимое кэша всех процессоров и как-то тормозить их на время этого обновления.
Хорошо если число ядер/процессоров 2, как в настольном компьютере, а если 8 или 16? И если все они обмениваются данными через одну шину?
Потери в производительности могут быть очень значительные.
Многоядерные процессоры
Как бы снизить нагрузку на шину?
Прежде всего можно перестать её использовать для обеспечения когерентности. Что для этого проще всего сделать?
Да-да, использовать общий кэш. Так устроены большинство современных многоядерных процессоров. 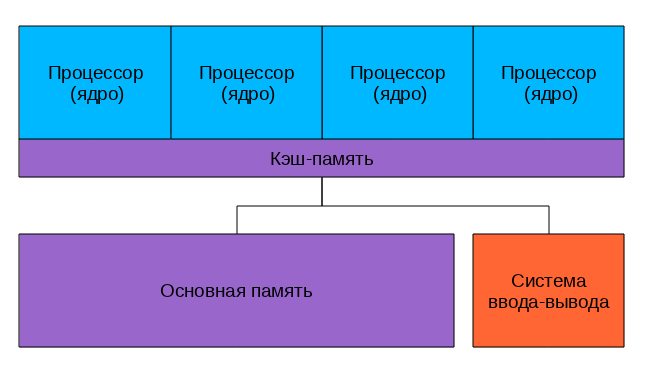
Посмотрим на картинку, найдем два отличия от предыдущей.
Да, кэш теперь один на всех, соответственно, проблема когерентности не стоит. А еще круги превратились в прямоугольники, это символизирует тот факт, что все ядра и кэши находятся на одном кристалле. В реальной действительности картинка несколько сложнее, кэши бывают многоуровневыми, часть общие, часть нет, для связи между ними может использоваться специальная шина, но все настоящие многоядерные процессоры не используют внешнюю шину для обеспечения когерентности кэша, а значит — снижают нагрузку на нее.
Многоядерные процессоры — один из основных способов повышения производительности современных компьютеров.
Уже выпускаются 6 ядерные процессоры, в дальшейшем ядер будет еще больше… где пределы?
Прежде всего «ядерность» процессоров ограничивается тепловыделением, чем больше транзисторов одновременно работают в одном кристалле, тем больше этот кристалл греется, тем сложнее его охлаждать.
А второе большое ограничение — опять же пропускная способность внешней шины. Много ядер требуют много данных, чтоб их перемалывать, скорости шины перестает хватать, приходится отказываться от SMP в пользу
NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — архитектура, в которой, при общем адресном пространстве, скорость доступа к памяти зависит от ее расположения Обычно у процессора есть » своя» память, обращение к которой быстрее и «чужая», доступ к которой медленнее.
В современных системах это выглядит примерно так
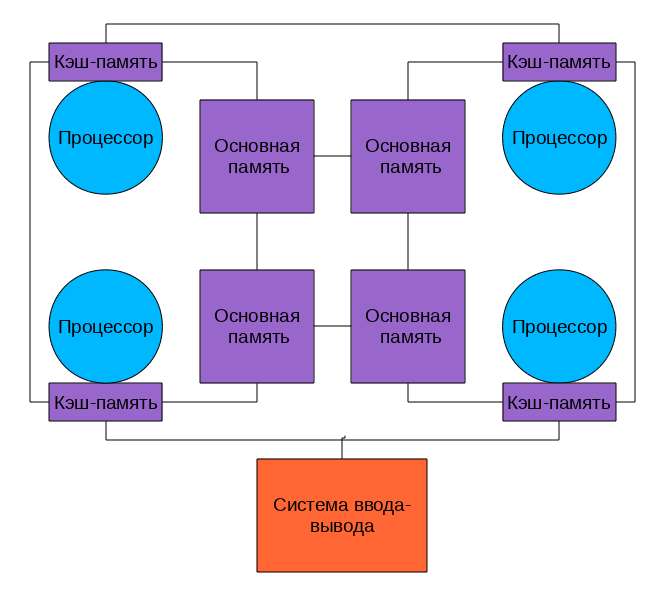
Процессоры соединены с памятью и друг с другом с помощью быстрой шины, в случае AMD это Hyper Transport, в случае последних процессоров Intel это QuickPath Interconnect
Т.к. нет общей для всех шины то, при работе со «своей» памятью, она перестает быть узким местом системы.
NUMA архитектура позволяет создавать достаточно производительные многопроцессорные системы, а учитывая многоядерность современных процессоров получим уже очень серьезную вычислительную мощность «в одном корпусе», ограниченную в основном сложностью обеспечения кэш-когерентности этой путаницы процессоров и памяти.
Но если нам нужна еще большая мощность, придется объединять несколько мультипроцессоров в
Мультикомпьютер
Мультикомпьютер — вычислительная система без общей памяти, состоящая из большого числа взаимосвязанных компьютеров (узлов), у каждого из которых имеется собственная память. При работе над общей задаче узлы мультикомпьютера взаимодействуют через отправку друг другу сообщений.
Современные мультикомпьютеры, построенные из множества типовых деталей, называют вычислительными кластерами.
Большинство современных суперкомпьютеров построены по кластерной архитектуре, они объединяют множество вычислительных узлов с помощью быстрой сети (Gigabit Ethernet или InfiniBand) и позволяют достичь максимально возможной при современном развитии науки вычислительной мощности.
Проблемы, ограничивающие их мощность, тоже немаленькие
Это:
1) Программирование системы с параллельно работающими тысячами вычислительных процессоров
2) Гигантское энергопотребление
3) Сложность, приводящая к принципиальной ненадежности
Сводим все воедино
Ну вот, вкратце пробежались почти по всем технологиям и принципам построения мощных вычислительных систем.
Теперь есть возможность представить себе строение современного суперкомпьютера.
Это мультикомпьютер-кластер, каждый узел которого — NUMA или SMP система с несколькими процессорами, каждый из процессоров с несколькими ядрами, каждое ядро с возможностью суперскалярного внутреннего параллелизма и векторными расширениями. Вдобавок ко всему этому во многих суперкомпьютерах установлены GPGPU — ускорители.
У всех этих технологий есть плюсы и ограничения, есть тонкости в применении.
А теперь попробуйте эффективно загрузить-запрограммировать всё это великолепие!
Задача нетривиальная… но очень интересная.
Что-то будет дальше?



