Взаимодействие памяти и процессора




![]()
![]()
Процессор взаимодействует с оперативной памятью не напрямую, а через специальный контроллер, подключенный к системной шине процессора приблизительно так же, как и остальные контроллеры периферийных устройств. Причем механизм обращения к портам ввода/вывода и к ячейкам оперативной памяти с точки зрения процессора практически идентичен. Процессор сначала выставляет на адресную шину требуемый адрес, а в следующем такте уточняет тип запроса: происходит ли обращение к памяти, портам ввода/вывода или подтверждение прерывания. В некотором смысле оперативную память можно рассматривать как совокупность регистров ввода/вывода, каждый из которых хранит некоторое значение.
Обработка запросов процессора ложится на набор системной логики (так же называемый чипсетом), среди прочего включающий в себя и контроллер памяти. Контроллер памяти полностью «прозрачен» для программиста, однако знание его архитектурных особенностей существенно облегчает оптимизацию обмена с памятью.
Рассмотрим механизм взаимодействия памяти и процессора на примере чипсета Intel 815EP (рис. 2.9). Когда процессору требуется получить содержимое ячейки оперативной памяти, он, дождавшись освобождения шины, через механизм арбитража захватывает шину в свое владение (что занимает один такт) и в следующем такте передает адрес искомой ячейки. Еще один такт уходит на уточнение типа запроса, назначение уникального идентификатора транзакции, сообщение длины запроса и маскировку байтов шины. Подробнее об этом можно прочитать в спецификациях на шины Р6 и EV6, здесь же достаточно отметить, что эта фаза запроса осуществляется за три такта системной шины.
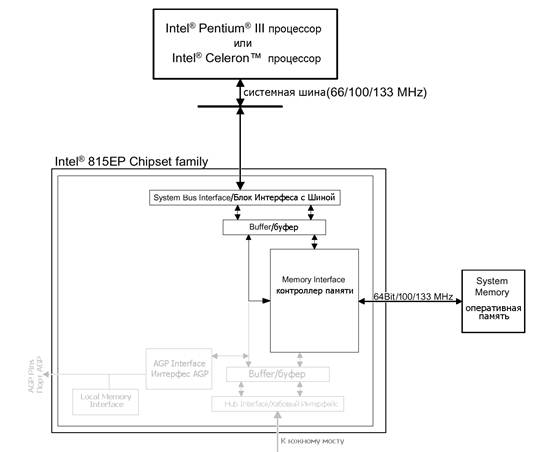
Устройство северного моста чипсета Intel 815EP, содержащего (среди прочего) контроллер памяти
Независимо от размера читаемой ячейки (байт, слово, двойное слово) длина запроса всегда равна размеру линейки Ь2-кэша (подробнее об устройстве кэша мы поговорим в одноименной главе), что составляет 32 байт для процессоров K6/P-II/P-III, 64 байт — для AMD Athlon и 128 байт — для Р-4. Такое решение значительно увеличивает производительность памяти при последовательном чтении ячеек и практически не уменьшает ее при чтении ячеек вразброс, что и неудивительно, т. к. латентность чипсета в несколько раз превышает реальное время передачи данных, и им можно пренебречь.
Контроллер шины (BIU — Bus Interface Init), «вживленный» в северный мост чипсета, получив запрос от процессора, в зависимости от ситуации либо передает его соответствующему агенту (в нашем случае — контроллеру памяти), либо ставит запрос в очередь, если агент в этот момент чем-то занят. Потребность в очереди объясняется тем, что процессор может посылать очередной запрос, не дожидаясь завершения обработки предыдущего, а раз так, то запросы приходится где-то хранить.
Но, так или иначе, наш запрос оказывается у контроллера памяти (МСТ — Memory Controller). В течение одного такта он декодирует полученный адрес в физический номер строки/столбца ячейки и передает его модулю памяти по сценарию, описанному в разд. «Устройство и принципы функционирования оперативной памяти» этой главы.
В зависимости от архитектуры контроллера памяти он работает с памятью либо только на частоте системной шины (синхронный контроллер),либо поддерживает память любой другой частоты (асинхронный контроллер). Синхронные контролеры ограничивают пользователей ПК в выборе модулей памяти, но, с другой стороны, асинхронные контроллеры менее производительны. Почему? Во-первых, в силу несоответствия частот, читаемые данные не могут быть непосредственно переданы на контроллер шины, и их приходится сначала складывать в промежуточный буфер, откуда шинный контроллер сможет их извлекать с нужной ему скоростью. (Аналогичная ситуация наблюдается и с записью.) Во-вторых, если частота системной шины и частота памяти не соотносятся как целые числа, то перед началом обмена приходится дожидаться завершения текущего тактового импульса. Таких задержек (в просторечии пенальти) возникает две:
- при передаче микросхеме памяти адреса требуемой ячейки
- при передаче считанных данных шинному контроллеру.
Все это значительно увеличивает латентность подсистемы памяти — т. е. промежутка времени с момента посылки запроса до получения данных. Таким образом, асинхронный контроллер, работающий с памятью SDRAM PC-133 на системной шине в 100 МГц, проигрывает своему синхронному собрату, работающему на той же шине с памятью SDRAM PC-100.
Контроллер шины, получив от контроллера памяти уведомление о том, что запрошенные данные готовы, дожидается освобождения шины, и передает их процессору в пакетном режиме. В зависимости от типа шины за один такт может передаваться от одной до четырех порций данных. Так, в процессорах Кб, Р-И и Р-Ш осуществляется одна передача за такт, в процессоре Athlon — две, а в процессоре Р-4 — четыре.
С этого момента данные поступают в кэш и становятся доступными процессору.
Контроллер системной шины, отвечающий за обработку запросов и перемещение данных между процессором и чипсетом, состоит из следующих функциональных компонентов: трансфера данных (Processor Source Synch Clock Transceiver), планировщика запросов (Command Queue — CQ), контроллера очередей запросов (Control System Queue — CSQ) и агента транзакций (transaction combiner agent — XCA). Остальные компоненты контроллера шины, присутствующие на рис. 2.11, необходимы для поддержки зондовой отладки, которая к обсуждаемой теме не относится, а потому здесь не рассматривается.
Трансфер данных — в каком-то высшем смысле представляет собой «голый» контроллер шины, понимающий шинный протокол и берущий на себя все заботы по общению с процессором. Полученные от процессора запросы передаются планировщику запросов, откуда они отправляются соответствующим агентам по мере их освобождения.
Ответы агентов сохраняются в трех раздельных очередях: очереди чтения (SysDC Read Queue — SRQ), очереди записи памяти (Memory Write Queue — MWQ) и очереди записи шины PCI(PCI/A-PCI Write Queue — AWQ). Обратите внимание: в данном случае речь идет о записи/чтении в процессор, а не наоборот! Таким образом, очередь записи памяти хранит данные, передаваемые из памяти в процессор, но не записываемые процессором в память!
Организация памяти
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек. 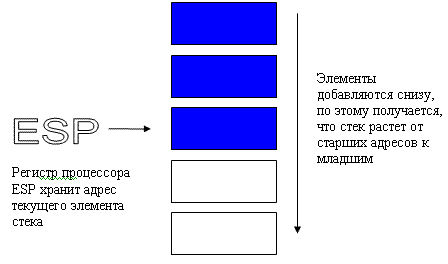
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес —> Линейный (виртуальный)—> Физический
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Сегмент данных
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес. 
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: 
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.



